
Khám phá Reinforcement Learning (Kỳ 1)
Posted on: 15/6/2019

Reinforcement Learning (tiếng Việt: Học Tăng Cường) là một trong ba mô hình học chính của Machine Learning, bên cạnh Supervised Learning (Học Giám Sát) và Unsupervised Learning (Học Không Giám Sát). Trong chuỗi 3 bài viết chuyên môn tới đây, PiMA sẽ cùng bạn đọc khám phá những công thức và mô hình Toán học ẩn sau Reinforcement Learning. Reinforcement Learning là gì?
Một cách ngắn gọn nhất, Reinforcement Learning là quá trình đưa ra các quyết định tối ưu thông qua một cơ chế tự thử nghiệm và đánh giá (trials and feedbacks).
Ví dụ 1: khi bé MaPi (mới 4 tuổi) chơi và tiếp xúc với môi trường xung quanh, không có người trực tiếp bảo bé phải chơi như thế nào; thay vào đó, bé có các giác quan để cảm nhận các tác động (độ nóng, cơn đau) từ môi trường mang lại.
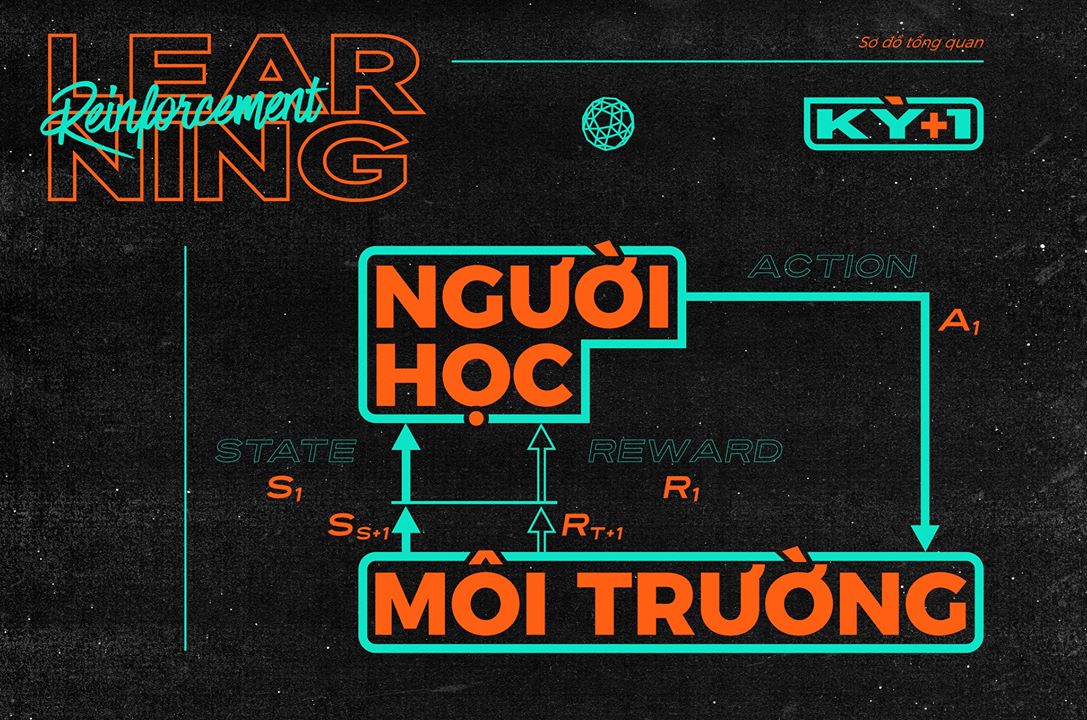
Một cơ chế tương tác giữa người học và môi trường tương tự như trên sẽ cung cấp thông tin về hành động và tác động, về hành động và hậu quả/thành quả, và về những việc cần làm để đạt được các mục tiêu đề ra. Để mô hình hóa ý tưởng này, chúng ta có thể xem xét quá trình tương tác theo từng mốc thời gian $t$, được đánh dấu bởi trạng thái của môi trường và chuyển sang mốc tiếp theo dựa trên bằng hành động của người học. Ta xây dựng ba yếu tố cơ bản sau:
- States: Tập hợp $S$ gồm tất cả các trạng thái $s_i$ có thể của môi trường học;
- Actions: Tập hợp $A$ gồm tất cả các hành động $a_j$ có thể của người học;
- Rewards: Tập hợp $R$ gồm các giá trị $r_{ij}$ để đánh giá hành động $a_j$ lên trạng thái $r_i$. Ta có sơ đồ tổng quan sau: tại thời điểm $t$, môi trường ở trạng thái $S_t := s_i$ trong $S$, người học chọn hành động $A_t := a_j$ thuộc $A$, nhận được thêm $R_t := r_{ij}$ và làm trạng thái chuyển sang sang $S_{t+1} := s_k$ nào đó. Một mục tiêu có thể là lựa chọn chuỗi hành động $A_t$ để tối ưu hóa tổng tất cả các $R_t$.
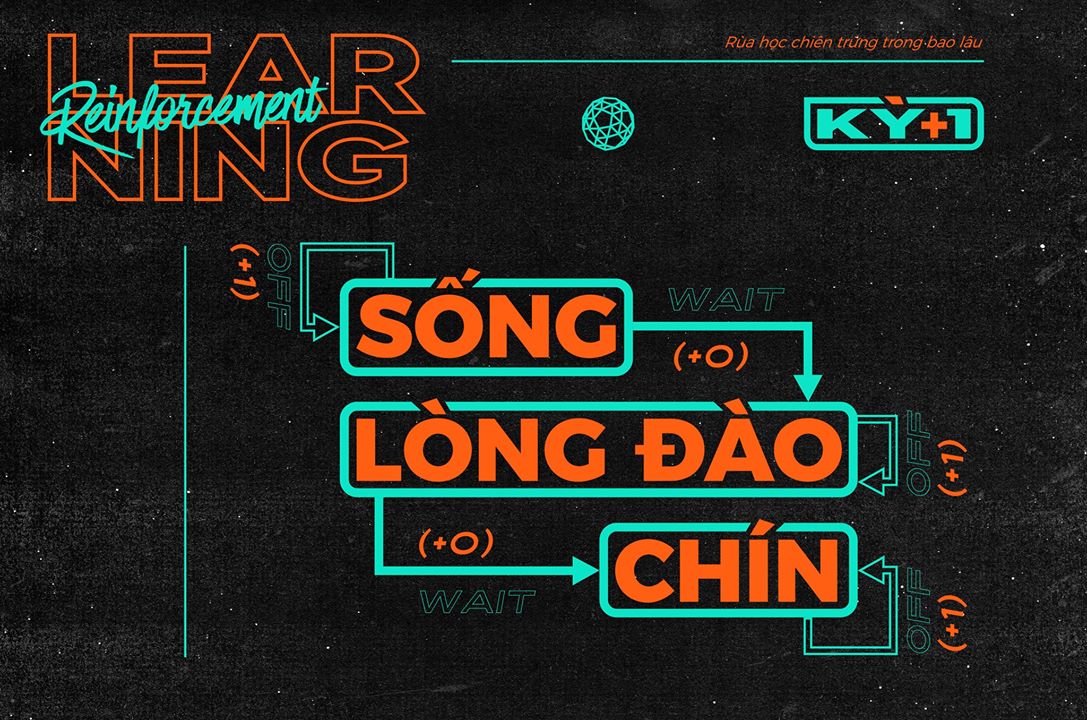
Ví dụ 2: bạn Rùa học chiên trứng trong bao lâu
- S = {sống, chín, trứng lòng đào};
- A = {đợi 1 phút, tắt bếp};
- R = {-1, 0, 1, 2}.
Ta có sơ đồ chuyển trạng thái và hiệu quả tương ứng, trong đó các mũi tên đi từ trạng thái cũ sang trạng thái mới kèm theo hành động và hiệu quả đi tương ứng. Từ sơ đồ này: chẳng hạn $s_3$ = trứng lòng đào, $r_{32}$ = 2. Ta dễ thấy chuỗi hành động đợi 1 phút và tắt bếp mang lại hiệu quả tốt nhất là +2.
Vài năm gần đây, các thuật toán biến thể cao cấp của Reinforcement Learning đã mang lại các thành tựu đột phá trong trí tuệ nhân tạo: nổi bật hơn cả là sự kiện Google’s AlphaGo đánh bai Lee Sedol - kỳ thủ cờ vây hàng đầu Thế Giới, hay OpenAI Five chiến thắng Team OG - đương kiêm vô địch Dota 2.
Thực tế trong cuộc sống, mỗi hành động có thể không chỉ dẫn đến một trạng thái cố định mà còn có thêm yếu tố ngẫu nhiên (chẳng hạn trứng không phải lúc nào cũng chiên sau 2 phút là chín; một số quả chín lâu hơn, sau 2 phút vẫn là lòng đào). Trong kỳ tiếp theo, chúng ta sẽ đưa thêm yếu tố ngẫu nhiên này vào mô hình Reinforcement Learning cơ bản thông qua Markov Decision Process.
Bài tập cho bạn đọc: giả sử 50% trứng lòng đào chín sau 1 phút, 50% còn lại chín sau 2 phút. Vẽ lại sơ đồ cho Ví dụ 2 (gợi ý: kèm theo một giá trị xác suất cho mỗi mũi tên chuyển trạng thái). Tài liệu tham khảo: Richard Sutton’s Reinforcement Learning: An Introduction.
TRẠI HÈ TOÁN HỌC VÀ ỨNG DỤNG 2019
Thông tin chi tiết: http://bit.ly/PiMA2019_Info
Đơn ứng tuyển: http://bit.ly/PiMA2019_Application
Hạn chót nộp đơn: 23h59’ ngày 20/6/2019
Mọi thắc mắc xin vui lòng liên hệ:
- Email: pima.vn@gmail.com
- Fanpage: fb.com/pimavn
- Hotline: 0961565087 (Thế Anh)